Training a Chatbot
Train chatbots using file upload, URL, and/or snippet options.
Last updated
Was this helpful?
Train chatbots using file upload, URL, and/or snippet options.
Last updated
Was this helpful?
Yola simplifies chatbot creation by allowing you to train your bot using data from websites, uploaded files, or text snippets. This makes it easy to automate responses and scale your customer support operations.
Manage your data sources within the Chatbots module by selecting a chatbot and navigating to the Data Sources tab. You can train your chatbot on the following sources:
Upload File: Train your chatbot using information from uploaded files, such as PDFs, CSVs, XLS, JSON, etc.
Add URL: Crawl and extract content from your website for training.
Paste Snippet: Train your bot using custom text snippets for specific use cases.
Text in images cannot be read by the chatbot. Ensure all critical information is available as text in your files and on your website.
The Existing Content section, located at the bottom of the page, displays previously added data sources. Use the search bar or the Type and Status filters to manage this content effectively.
Train your chatbot using documents that contain written text, such as PDFs, CSVs, XLS(X), TXT, JSON files, with a maximum size of 5MB per file. This option is particularly useful for providing information that isn’t available on your website.
Click "Upload File".
Enter a name and attach the file (supported formats: PDFs, CSVs, XLS(X), TXT, JSON files; max size: 5MB).
Click "Train chatbot on file".
Check the training status in the Existing Content section after uploading.
Click "Add URL".
Add a name for the URL.
Input the website URL.
Choose one of the following options:
Crawl: Train the chatbot on the selected website and its linked pages.
Single URL: Restrict training to the specific URL provided.
(Optional) Enable Automatically retrain every X hours to update the bot periodically. Frequencies available are 1 hour, 12 hours, 1 day, and 1 week depending on your subscription.
Click "Train chatbot on URL".
This process allows the chatbot to gather and learn from the content available on your website. You can monitor the training status in the Existing Content section.
Not all websites can be effectively scraped due to formatting inconsistencies, permission restrictions, or site mapping issues. If scraping fails, transfer the content to a document and upload it as a file instead.
If scraping fails or the chatbot is unable to answer questions for which the answer is in the URL, this may be due to difficulties accessing your website caused by restrictions imposed by a proxy server. There are a couple of possible workarounds you can try:
Retry adding the URL and toggle on the "Enable proxy bypass" option.
Check if the sync is now successful and whether the chatbot can answer questions based on the content in the URL(s).
If this doesn’t solve the issue, your website may be behind additional layers of security. Whitelisting Yola's IP might resolve this issue. Follow the steps below to whitelist the IP.
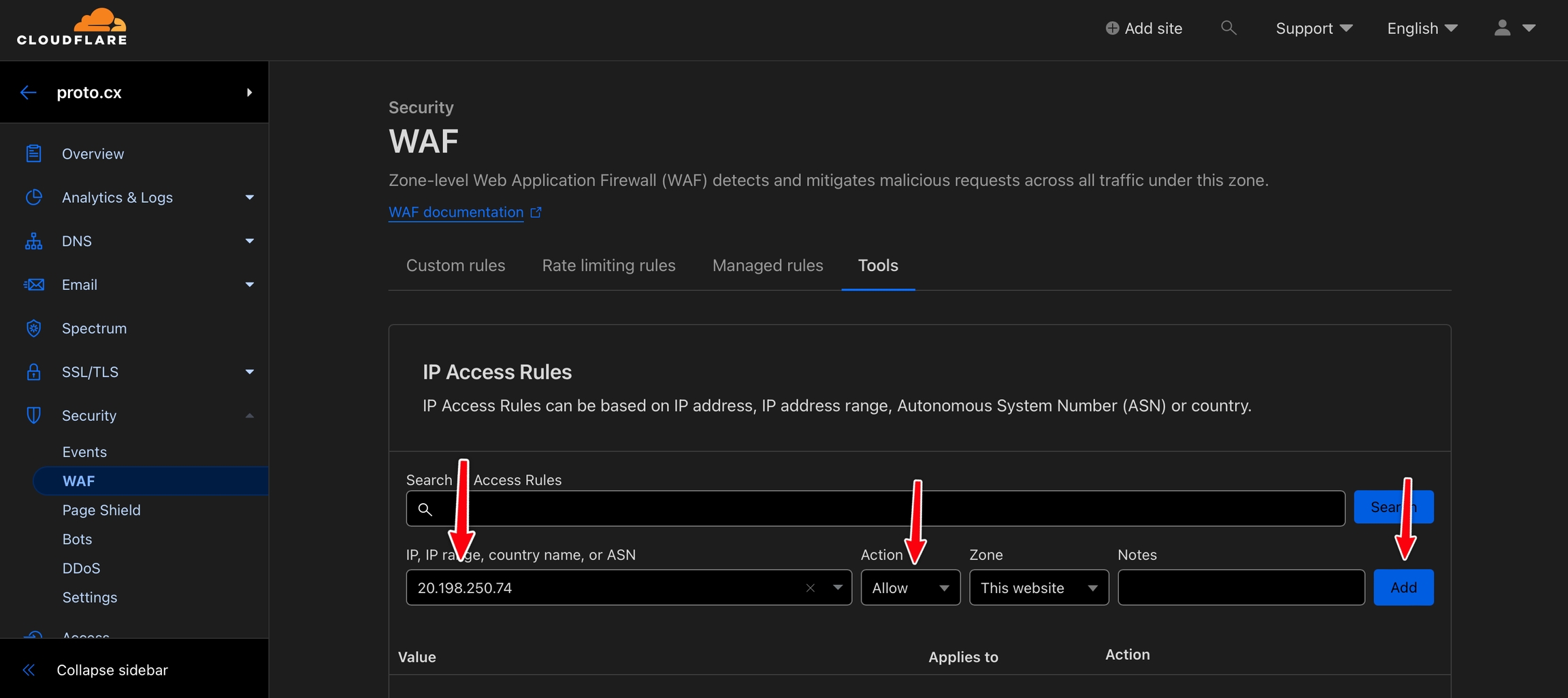
Add the IP address 20.198.250.74 to your website host's settings under the IP, IP range, country name, or ASN field.
Retry adding the data source with "Enable proxy bypass" disabled.
Disable the proxy bypass option as it uses different IPs for scraping, which will conflict with whitelisting.
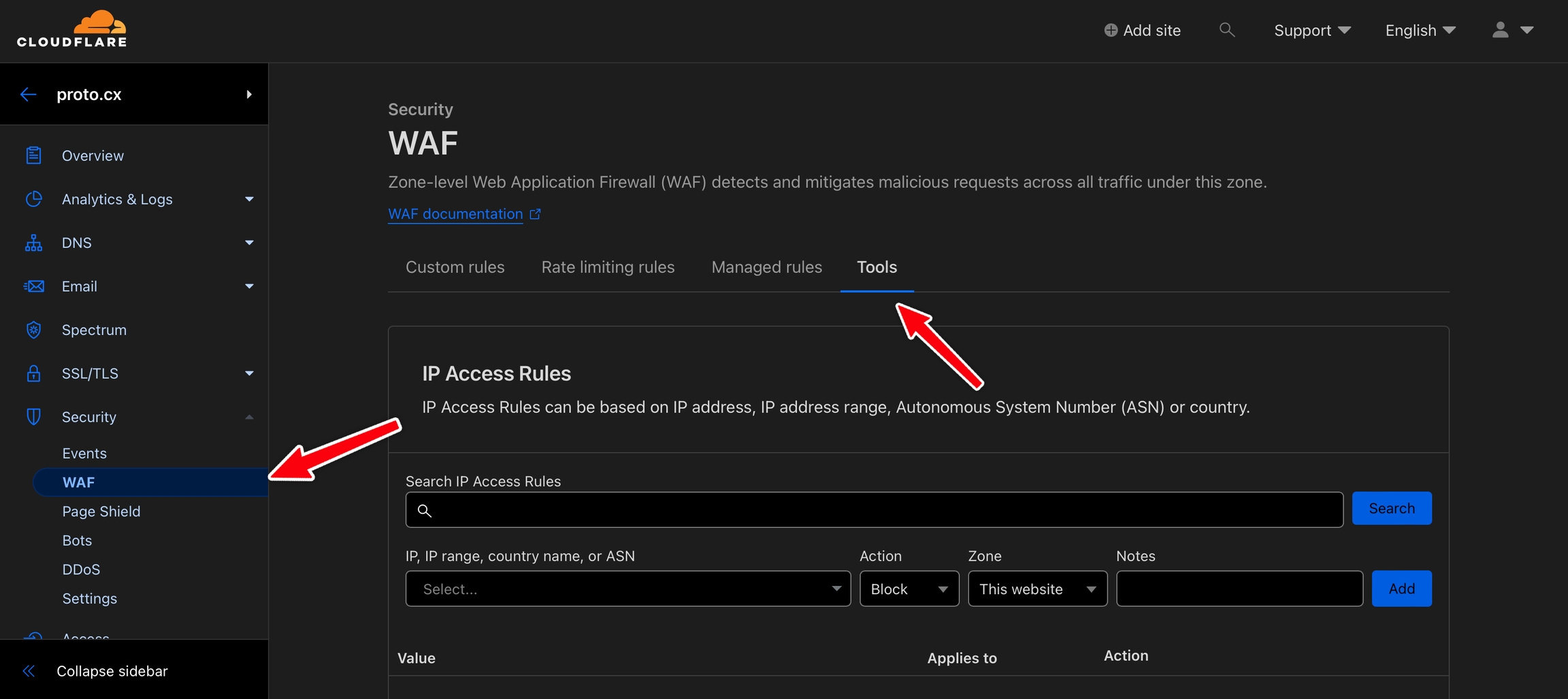
Here's an example of how to do this for Cloudflare:
Go to your site in Cloudflare
Navigate to Security → WAF → Tools.
Enter the IP address 20.198.250.74 in the IP, IP range, country name, or ASN field. Set Action to Allow, then click Add.
Back in Yola, add your website and be sure to disable Enable proxy bypass.
Use text snippets for quick, specific training data. This is particularly useful for temporary information, such as weekly promotions or announcements, which you want to add and remove without updating your website or core documents.
Click "Paste Snippet".
Insert a name and paste the snippet text.
Click the "Train chatbot on Snippet" button.
Check the training status in the Existing Content section.
Ensure that text snippets do not contradict information on your website or uploaded documents to prevent the chatbot from being confused about which information is correct.
After clicking "Train chatbot on URL/file/snippet", the added source appears in the Existing Content table. This section displays:
Name: The name of the source.
Last Updated Date: The date the source was last updated.
Status: The current processing status.
Pending: The training process is ongoing.
Success: The content was successfully processed.
Failure: The training process failed.
Loading: Retraining is in progress and will update to Success upon completion.
Open an added source to view detailed information in the right sidebar, including the extracted content.
Hover over the Name field to rename it.
For URLs, use the Retrain option to refresh the data.
Use the search bar or the Type and Status filters to locate specific entries.
Select the desired source in the Existing Content table.
Click "Delete Content".
Confirm deletion by clicking the "Delete" button in the pop-up dialogue.